
s1:Simple test-time scaling为什么有效?
前言
这是我最近读到的两篇很有意思的论文:《s1: Simple test-time scaling》和《Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?》,里面的结论刷新了我之前的看法,恰好之前做了一次论文分享,就将分享的内容整理为文字,主要是结合后一篇论文谈谈我对前一篇论文的想法。
研究背景
在OpenAI-o1出来之前,提升大模型的能力主要是在训练的时候加大计算量以及投入。o1的出现提示人们可以通过加大测试的时候的计算量得到更好的效果(test-time scaling)。
作者想要找到一个最简单的方法来实现测试时扩展和强大的推理性能。
研究过程
o1对比普通模型最大的区别就是有一个思考过程,并且o1在回答问题的时候输出的时间更长,输出的token更多。
一般思考模型进行思考的时候<think>和</think>来包围思考过程,用<answer></answer>来包围答案,一是一般思考的过程集中<think>和</think>当中,另一个是在这样设计方便验证大模型生成的答案。只要提取<answer></answer>之间的文字就行了。
作者就想,那针对<think>xxxx,所以1+1=2</think><answer>2</answer>这样一段模型的输出,这个标签不方便变动,<answer></answer>之间的文字也不方便变动,那能变的就只有<think>和</think>当中的token数。所以最简单的方法就是增加<think>和</think>当中的token数,达到test-time scaling。
首先作者先收集了一个数据集然后再在上面微调模型Qwen2.5-32B-Instruct,让其能生成<think></think>标签,模拟o1的思考过程。
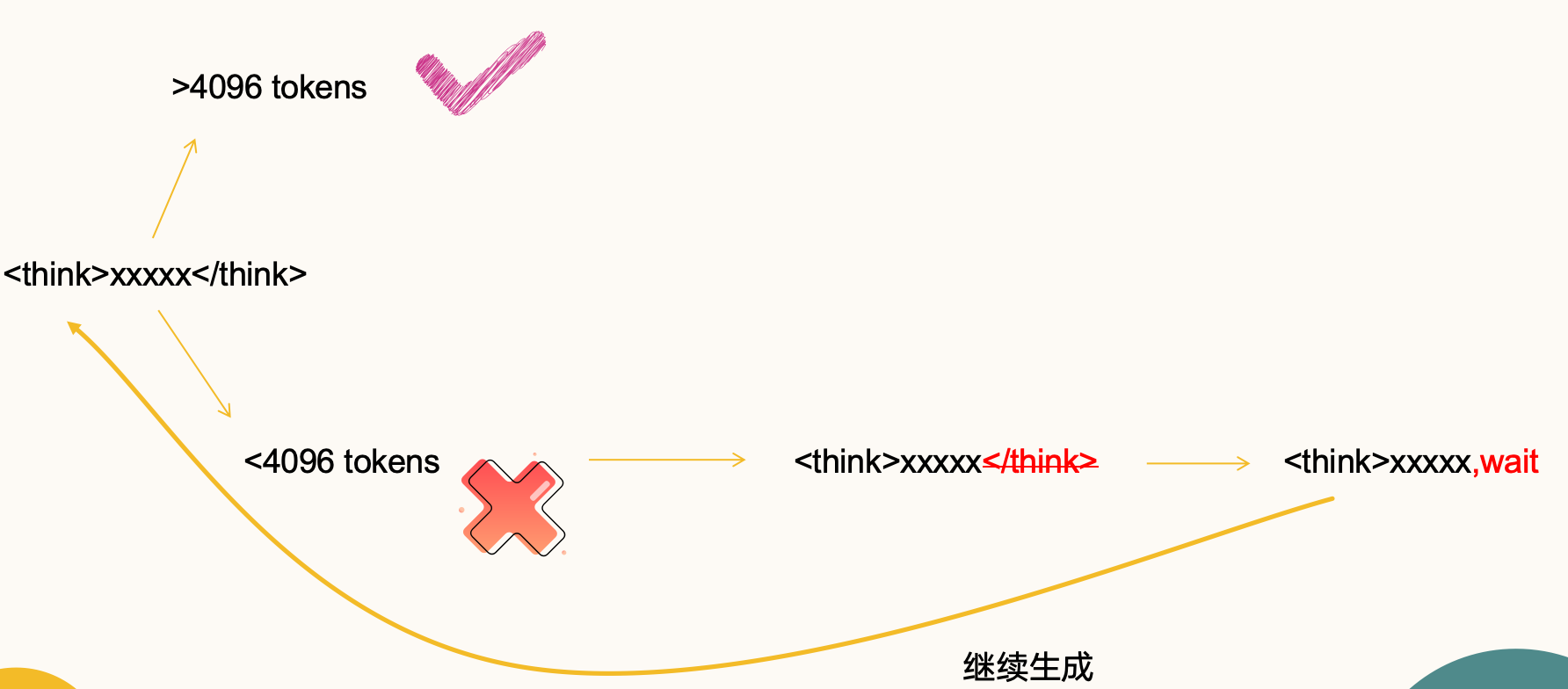
然后作者就提出预算强制算法,让模型一直生成,直到<think>中的token数大于预定值为止。在实操中,如果过早的生成了</think>,就将其替换为wait。然后然模型接着生成。但如果模型生成的思考标记超过了期望的限制,将通过添加思考结束标记分隔符强制结束思考过程。以这种方式结束思考使得模型过渡到生成答案。
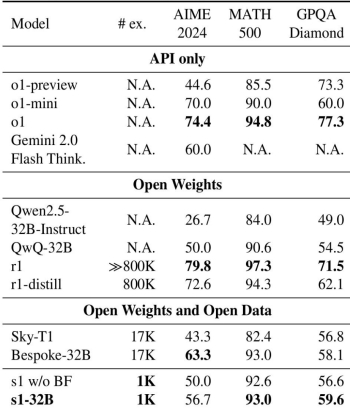
最后取得了很不错的成绩,s1-32B模型在AIME24基准测试中的表现接近Gemini 2.0 Flash Thinking
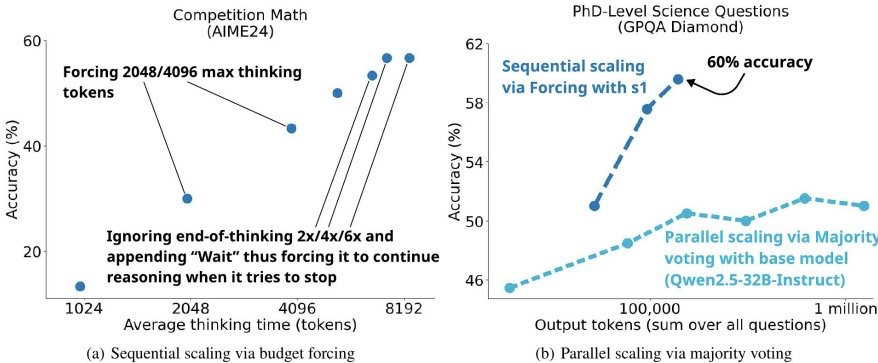
随着测试时间计算量(tokens)的增加,模型的准确率逐步提升,但到了六倍计算量时,性能趋于平稳。并且作者提到右边是同时生成多个答案并通过多数投票增加计算量,效果比较这种强制预算加wait的方法差。
为什么其行之有效?
结合清华在4月18日的论文《Does Reinforcement Learning Really Incentivize Reasonine Capacity in LLMs Beyond the Base Model?》谈谈我的想法
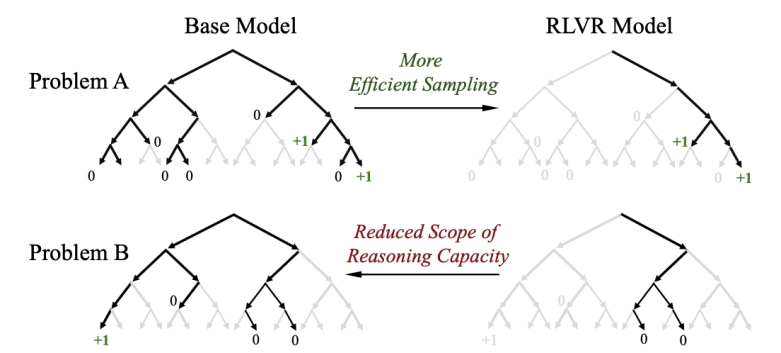
从论文中可以知道,目前的强化学习模型其实并没有增加LLM在基模型之外的推理能力,只是提高了采样的效率,让模型更可能一次答对。也就是模型本身就可以输出正确的结果,强化学习只是让模型更容易找到这条正确的路。
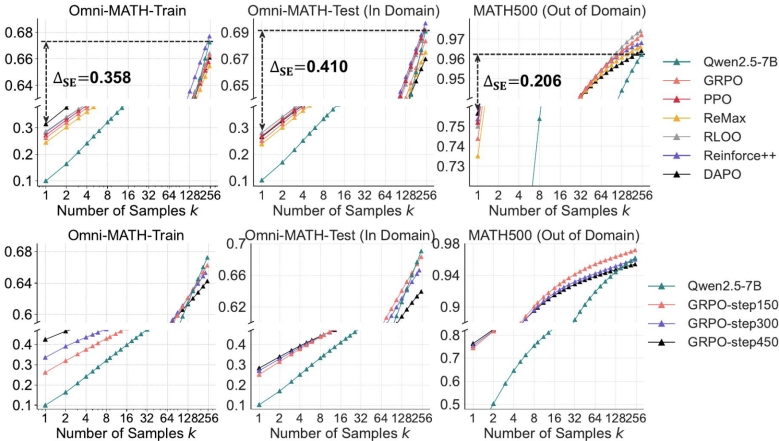
如果以pass@k为指标,也就是,如果模型在回答k次中能回答正确一次,就算过,如果k次都错了,就算失败。随着回答的次数k变多,基模型的通过率逐渐接近甚至超过了经过强化学习的模型。比如在左下角Omni-MATH-Train里,在回答一次的情况下,基模型通过的题目只有10%,但是回答256次的时候,基模型可以通过68%的题目。
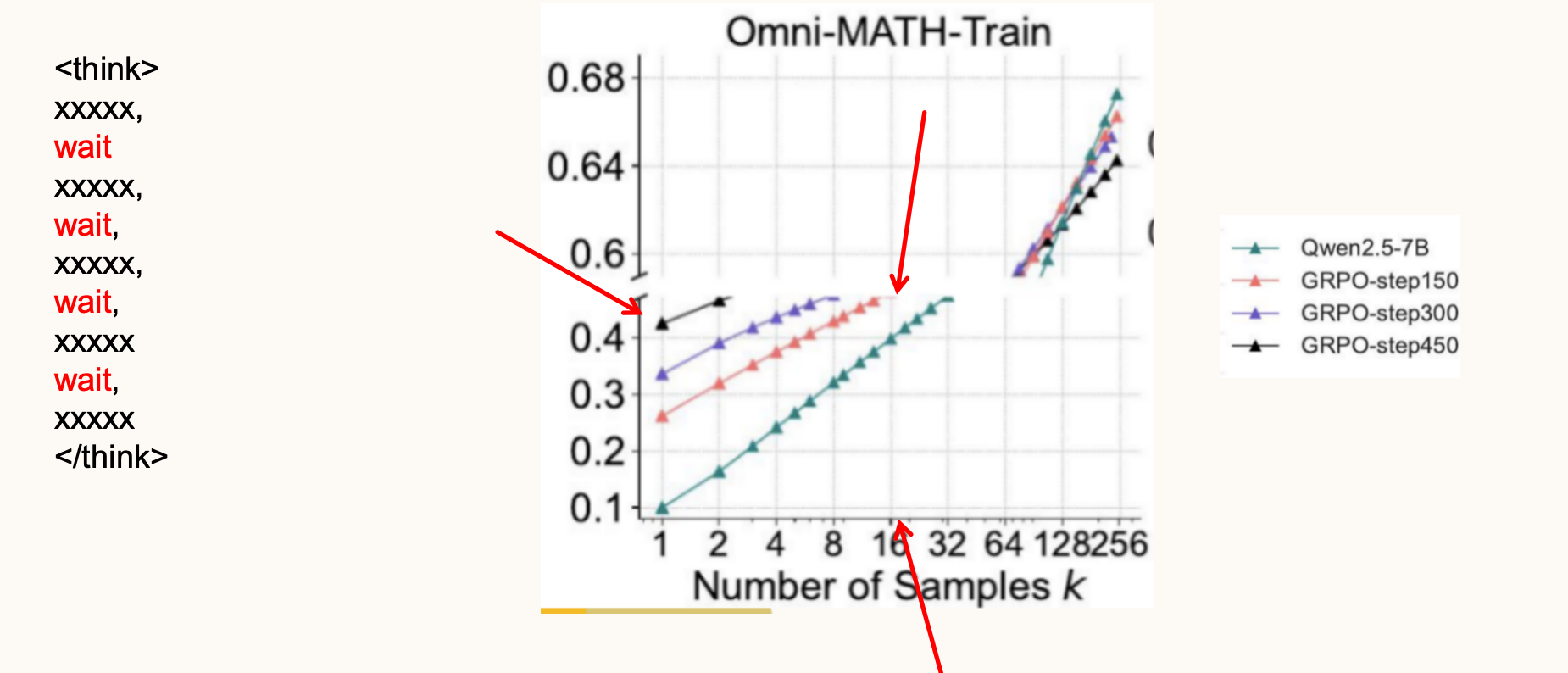
回到这篇论文上,虽然作者没有用强化学习等方法,但在think过程中加wait,强制模型继续思考,其实就增加了基模型的采样次数。以刚才论文中的图为例,让基模型采样16次的时候,它的通过率已经接近GRPO-step450的结果了,所以这个简单的方法效果才那么好。
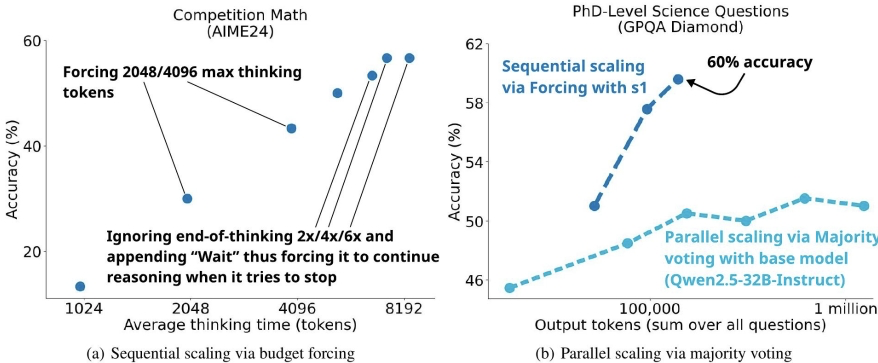
并行的结果之所以差,是因为生成多个答案,只有1个答案是对的,模型投票出这个答案是很难的。但是如果通过串行,加wait的方式,模型在输出的时候还会考虑之前思考过的内容,更可能找到它本来就知道的那条正确的道路。但随着token数增加,模型比如transformer层的计算量会更大,所以在6倍之后再加提升越来越缓慢和有限。
进一步,我认为test-time scaling可能本质是,通过增加采样次数或者增加采样效率,从基础模型的多个方法中找到正确的那个道路。从这个思想出发,还可以通过排除法排除错误答案使得模型生成的答案正确率更高。
所以其实答案就在那里,只是看模型怎么找到它。
一点我的思考
我们一直认为人的天赋有所不同,那这种天赋到底是我们的大脑能想到的东西(基础模型)不同,还是说我们大脑的采样效率不同呢?更聪明的人是思考的时候更容易找到正确的答案?还是其本身有更高的基础能力呢?