
Transformer炼丹小记--大即是好
前言
记一次人工神经网络课程大作业。
代码仓库在此:https://github.com/Very-White/2025_final_project 。
模型权重在此:https://www.modelscope.cn/models/SuperBaiBaiBai/zh-en-transformer 。
训练小记
在此之前,我以为凭借自己的炼丹经验,训练一个Transformer是轻而易举的事情。没想到为训练一个好的模型耗费了那么多精力,不过也学习到了很多训练技巧。
刚开始,我简单用预先提供的脚本进行训练,里面没有warmup,数据集很小(一个是10k,一个是100k),没有梯度检查点,甚至是将数据集全部加载进内存的。结果马上就过拟合了:

val_loss在下降一点后急速攀升,导致我一度以为是我超参数设置错了。于是我调整超参数再训练了几次,但效果不佳,仍旧过拟合。根据之前对Transformer的了解(从李沐老师视频中学习的),我知道Transformer的预设更少,所以需要用大的数据集才能训练好。于是我换用了当时我觉得比较大的100k数据集(10倍诶!可是10k数据集的10倍)。结果效果也没好多少:

val_loss也是下降了一点之后就开始飙升。虽然最低的val_loss比之前的val_loss小了1,但是这时候的BLEU分数只有0.09,是百分制的0.09,基本就相当于瞎猜!
我依旧不死心,我觉得可能是模型太大,调调超参数说不定就好了,比如加大点dropout、减小点emb_size等等。如果是CNN,这些方法可能就奏效了,但是Transformer不行。用Optuna调了几次参,依旧过拟合:

于是我本着小数据集上验证方法有效性,大数据集上拓展规模的想法,现在小数据集上找好超参数,再在大数据集上训练。结果用Optuna调了足足五十次,没有一次是有效的。




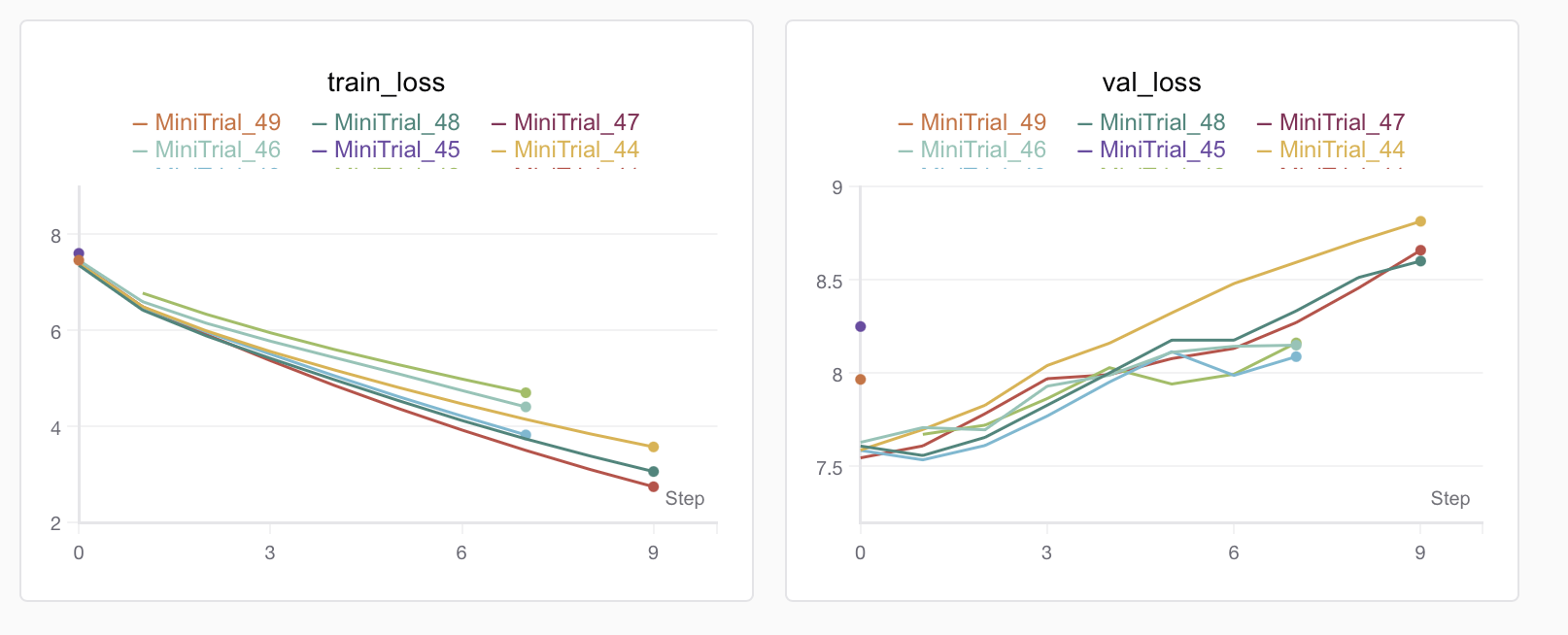
没有一组超参数可以在10k数据集上不过拟合的。我也是服了Transformer了,无奈之下,既然10k、100k都没有好效果,那干脆就用论文里的百万规模数据集来训练。于是我搜了一个500万平行语料的数据集:translation2019zh。但大数据集的使用没我想象的那么简单。
刚开始我只是改改数据集加载方式,从所有数据集加载进内存改成流式加载器。但我发现,模型变得很大,层数要减到很小才训练的动。这时我还不知道,我预处理出来的词表有100w~200w的大小。于是,我将Transformer减到4层,emb_size减到128,才勉强训练了起来。

但效果非常显著,过拟合消失了,val_loss降到7了!但坏消息是此时的模型还是比较笨,BLEU分数才0.9(虽然是之前的十倍),经常胡乱输出。
于是我去搜索前人经验,并找到了OpenAI的Scaling Law论文,从中知道了Transformer模型训练最重要的就是模型要大、数据集要大、训练时间要长,并且除了batch_size之外的超参数对模型性能影响有限。我现在有大数据集了,但模型还不够大,才4层。
但是什么导致我的显存占用那么高呢?我刚开始以为是优化器、中间值。所以我增加了梯度检查点、混合精度训练,并及时清理显存。做了这些,我成功的将emb_size从128拓展到了196。但我还是很困惑,明明Transformer论文中用到的显卡只有16G的内存,不及如今3090的24G内存,为什么他们能训练emb_size为1024的模型而不爆显存呢?带着困惑,我对加大后的模型进行了训练:

好消息是val_loss低了0.28左右,此时的BLEU分数也来到了1.5左右,坏消息是,模型还是胡乱输出,并且val_loss还是很高。在对模型的显存占用进行了计算后,我发现假设词表是3万,那模型最多就占用80多M的显存。但是为什么模型训练时显存占用了80%呢。
抱着疑问,我用Pytorch提供的工具对显存占用进行了查看。这不看不知道,一看吓一跳。

模型占用了4G的显存。但理论上我的模型只有20M的参数,怎么算都算不出那么大的占用。久久思索未果,我觉得进行调试,看看为什么占用那么大。唯一有可能出问题的就是词表大小,而我此前还没有进行确认过。打完断点调试发现,我的中文词表有100w,英文词表有200w,是我预估的10倍。难怪显存占用那么大。
之后发现,是我预处理的时候将很多只出现了一次的token也加入了词表中,导致词表过大。于是我重新设置了阈值以减小词表。令我啼笑皆非的是,词表大小减小到30w之后,显存占用变成了2G。难怪之前的效果一直不好。

减小了词表之后,我就可以增大emb_size了,甚至我将模型调到了这样,还没有爆显存:
1 | # ------------- 模型结构 ---------------- |
太好了,是大模型,我的实验有救了!我拿这个加大后的模型进行了训练(还加了warmup,这很重要!),效果出奇的好:

val_loss直接降低到了原来的$\frac12$。感受一下翻译效果,也超级棒:

如果有更大或更多的卡,或许效果能更好,但是我已经不打算再卷了,圆满了!
小结
炼丹真是件高深的事情,小小Transformer也有那么要注意的细节。不过通过Transformer,我也学到了很多,比如混合精度训练、梯度检查点、查看模型显存占用、自动调参。
最后感慨一下,《Attention Is All You Need》这篇论文已经家喻户晓,Transformer也已经成为各种神经网络的重要组件了。甚至哪里的面试都会问你Transformer的QKV是怎么做矩阵乘法的。
不过如何训练Transformer的资料并不多,也没什么人总结哪些是坑,哪些技巧需要用到。老师上课也就老调重弹,讲讲QKV,讲讲Attention,讲讲Mask,但是像Scaling Law或Warmup却不怎么提及,仅仅教室里学到的还是太浅表了呀。