
目标检测入门
基础概念
目标

检测任务一般分为两步:
- 检测出预测框(回归)
- 将预测框中的物体分类(分类)
同时用到了回归和分类。比如在这张图中就需要框出人和猫两个检测框,然后再对检测框做分类
所以标签(ground_truth)需要检测框坐标(bbox)和类别标签。类别标签有一个集合,比如有80个类别,模型就只会在图像中检测出这80个类别。
一些概念
Region proposals(RP)

中文叫做备选框。输入一张图像,可以得到很多候选框,每一个候选框可以看成一个被检测出来的目标,之后这些候选框就被拿去分类。就可以知道这个候选框对应的类别。就完成了目标检测的任务
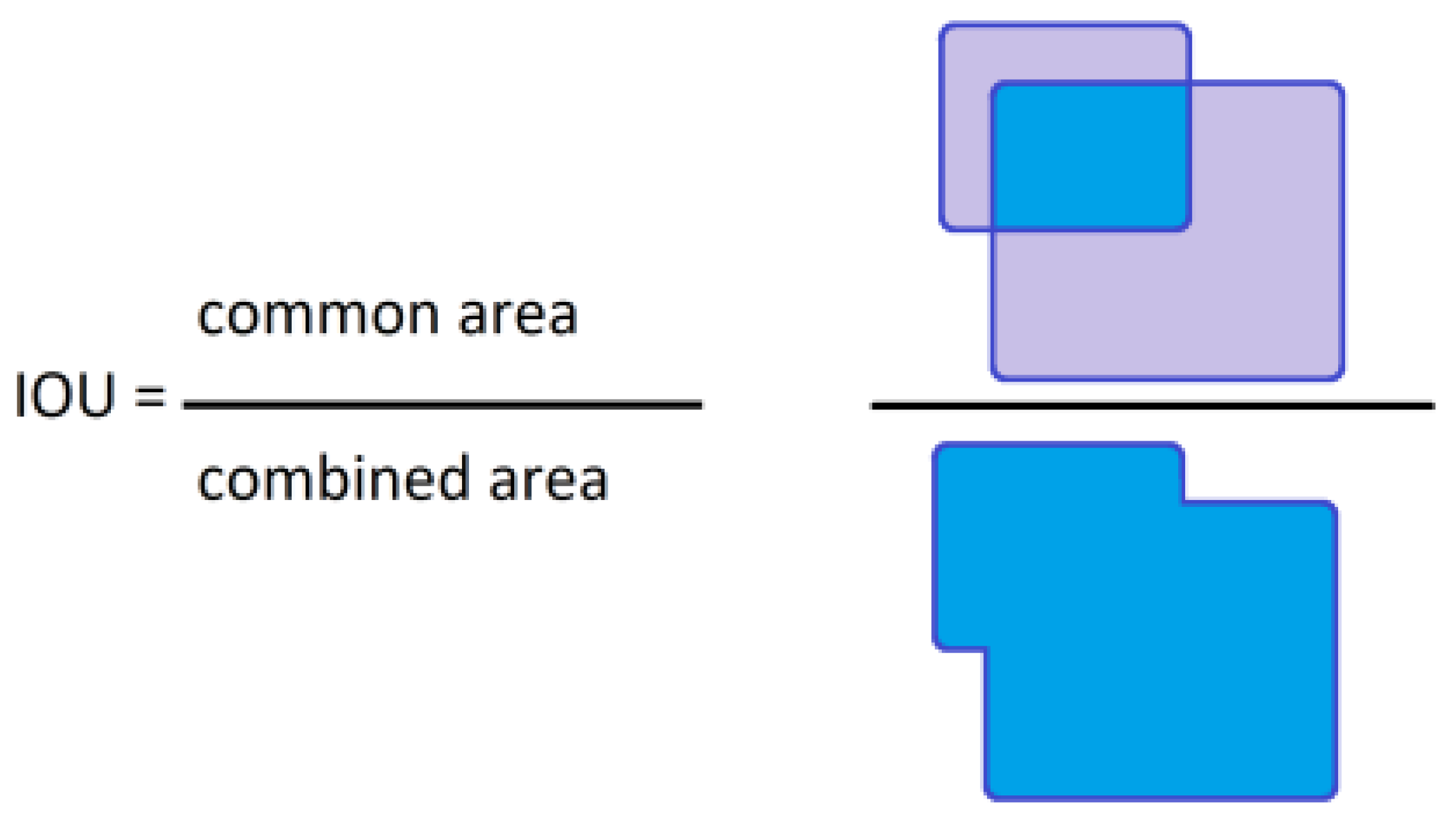
IoU
IoU的计算公式为两个框的交集除以并集
NMS(non-maximum suppression)

中文叫非极大值抑制。因为一个人可能有多个框都预测到这一个人,所以要用一种方法合并这些框,或者说叫过滤冗余框。
但NMS也有缺点,比如两个人重叠在一起了,就有可能被NMS过滤成同一个人。
分类
1-Stage和2-Stage
1-Stage的模型分为Anchor-based和Anchor-free的。Anchor-based相当于用预定义的Anchor代替了RP,之后预测Anchor的类别和预测offset。
2-Stage是先生成RP,然后再做分类。分类的时候一般还要微调(refine)检测框的大小(或称为预测offset)。
Anchor-based 和 Anchor-free

Anchor是定义出的一系列有固定长宽比、scale的框。对于每个小网格,都会画出很多Anchor框。上图中对每个小网格都画了三个Anchor框。
Anchor-based:如果有100个网格,每个网格有9个Anchor。那总共就预测900的Anchor的类别(和offset)就可以了。这样神经网络的输出维度就固定了,而且每个神经元预测的Anchor的大小也固定了,就不会出现一个神经元一会要预测大框一会要预测小框,Loss会比较稳定。经典的模型:RetinaNet。
但Anchor的长宽比、角度、scale这些都是预定义好的。有时候要识别的东西是不规则的形状的,或者长宽比时大时小,那表现就会差。而且计算量比较大。

Center net 论文配图
Anchor-free:抛弃了Anchor。经典的模型:Center Net、FCOS。Center Net把人物当成关键点来预测,然后再预测这个关键点的长宽,就能绘制出矩形框(但太依赖一个点的预测结果,所以召回率比较低);FCOS就用多个关键点来预测,就不依赖于一个点的预测结果了。
End-to-end
有一些模型在检测出来之后还要做后处理,端到端的模型就省略了这一步。
发展概述
开山之作
最早的是RCNN,将卷积网络(深度学习)引入到目标检测任务中。之后在这篇文章上衍生出了改进版Fast RCNN和Faster RCNN。
RCNN是典型的2-Stage模型。先得到候选框RP,然后再把裁剪出的图像送卷积神经网络CNN。
Fast RCNN等后续改进,因为觉得每次把图像裁剪下来耗时太长,所以在特征上进行裁剪。
one-stage的崛起
在RetinaNet这篇文章中,提出了新的Focal Loss,使得one-stage的方法追平甚至超过了two-stage的方法。
因为原来,在RP中,正样本(检测出来有物体的框)比较多。而Anchor因为是预定义的,所以很多可能框中根本就没有物体,所以负样本比较多。因为易分辨的负样本较多,所有时候是是模型把易分辨的负样本都找出来了,但真正困难的正样本并没有找出来,而因为最后是加权平均,所以Loss还是低。
所以就对Loss进行调整,调整难分辨的样本的权重更高,易分辨的样本的权重变低,如果模型想要Loss低,就要“啃硬骨头”。
当时很多one-stage算法都是Anchor-based算法。
端到端
之前的算法都需要NMS来解决冗余框问题。因为在预测不同框的时候没有信息传递。后面的模型用LSTM、Transformer这些模型来完成信息的交流。
后面还有比较新的Pix2Seq、GLIP等这种特别的模型。
参考
- 【入门级目标检测发展概述及概念简介】(超棒!目标检测小白也能听懂!)